2주차 '데이터수집을 위한 기초 파이썬'에서 배웠던 것과 마찬가지로 앞으로 데이터사이언스를 하기위해서, 필요한 파이썬 코딩에 대해 배워보았다.
지금까지는 Pycharm(개발도구)를 이용하여 python언어를 사용했다면, 이제는 jupyter을 이용하려고한다.
jupyter는 파이썬 코드 실행과 함께 문서작업이 용이하기때문에, 앞으로 데이터사이언스를 활용하고 그 결과를 문서형태로 내보낼 때 좋을 것이라고 생각한다.
jupyter는 python.interactive한 언어.
pycharm는 python.script한 언어
Python has two basic modes: script and interactive. The normal mode is the mode where the scripted and finished .py files are run in the Python interpreter. Interactive mode is a command line shell which gives immediate feedback for each statement, while running previously fed statements in active memory.
8주차 정리
아나콘다 jupyter설치 및 실행시 오류
1. 아나콘다 설치시 설치 폴더를 따로만들어놔야하고, 접근경로에 한글이 씌여져있으면 안된다.
2.내 컴퓨터에서는 anaconda navigater로 jupyter를 켤수없었고, jupyter Notebook으로 켤 수 있었다.
3. python3을 새로 만들 때, 하지말아야 하는 행동 :
3-1 jupyter Notebook cmd창을 끄는 것
3-2 <보안>에서 랜섬웨어 폴더 감시를 키는 것
jupyter에서 우리가 writing할 수 있는 공간을 cell이라고 한다.
cell에서 우리가 쓸 수 있는 형식은 code, markdown , Raw NBconvert , heading 4가지인데, 우리는 code와 markdown에 대해서 배웠다. code는 우리가 평소에 파이썬 코드를 짤 때 쓰는 방식으로 쓰면되고, markdown은 문서 작성을 하기위한 글을 적어넣는 방식이다.
| # | 문자크기 | --- | 구분선 |
| * , ** | 기울기 , 진하게 |  | 이미지넣기 |
| ` ` | 음영처리 | [텍스트](링크주소) | code넣기 |
| - | list만들기(순서x) | > | 인용구 |
| 1. | list만들기(순서o) |
'''python print('hello world!') ''' |
code넣기 |
pycharm을 통해서 pip 로 깐 requests와 BeautifulSoup은 주피터에서 인식되었지만, 나머지는 인식이안되서 따로 anaconda prompt를 통해 깔아준다.
밑에 설명이 잘되어있는 블로그를 소개해준다.
https://blog.naver.com/ssdyka/221225295688
3주차 Numpy와 Pandas
Pandas
파이썬으로 마치 프로그래밍 버전의 엑셀을 다루듯 고성능의 데이터 구조를 만들 수 있는 유명 라이브러리
raw한 data를 분석하게 해줌
pandas와 excel의 차이 : pandas는 데이터를 이용해서 무언가를 만들어갈 수 있다면, 엑셀은 마지막단계에서 데이터정리를 하고 표현하는 느낌
Series와 DataFrame으로 구성
DataFrame에서 df[]는 열(column) / df.loc[]는 행(row)
데이터가 2개이상이면 무조껀 [[]]
df2.loc['김','수학'] : 여기서는 ,를 기준으로 위치로 씌였고
df2.loc[(df2['영어']>=100) , '수학'] - :조건 - :대상
(여기서 다중 비교연산은 안되더라 80<df2['영어']<=100 (x) (80<df2['영어']) &(df2['영어']<=100)(o)
다중list와 numpy.array 차이
느낀점
1.list를 쓰면 다차원을 다루기 위해서는 다차원([0][1][3])를 써야하는 반면, numpy.array를 쓰면 1차원의 데이터(1,2,3,4)를 통해 다차원을 다룰 수 있다.
2. 좀 더 수를 수답게(행렬 계산도 numpy.array에서만 가능한 성질)
library를 이용하기
pandas를 이용하여,데이터를 쓰기 좋은 형태로 만들고(DataFrame) 이 형태를 이용하여, matplotlib 나 seaborn을 이용하여 시각화하기

스터디에서 배운 것
1. pd.read_csv('.csv')를 통해 데이터를 불러왔다면, 반대로 dataframe은 df.to_csv('.csv')로 저장할 수 있다.
2. seaborn의 data=train 을 이용하려면, 데이터추출을 하기보다는 원본csv에서 알맞은 열(column)을 만들어서 사용하는 것이 좋을 것 같다. 그래야 각 열(row)에 있는 데이터들이 서로 연관되어 그래프를 그릴 수 있기 때문이다.
3 seaborn 에서는 data= 을 통해서 csv 나 dataframe을 읽을 수 있었고 matplotlib 에서도 dataframe을 df.plot() 형태로 데이터값을 이용할 수 있다.
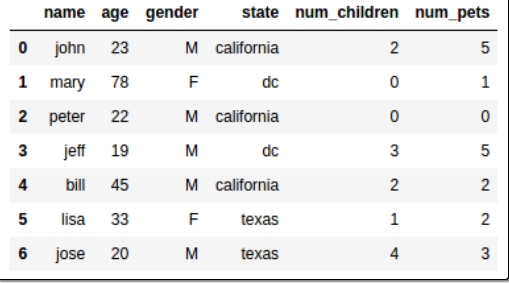
결론은 DB에서 Table 형태의 Data로 저장해야만, Data를 시각화 하기쉽다.
그렇지 않으면 우리가 다 값을 입력해야되는데, 그러면 시간과 정확성이 떨어진다.
'코알라UNIV' 카테고리의 다른 글
| 10주차 데이터로 꽃의 종류를 구분해보자 (0) | 2019.12.23 |
|---|---|
| 9주차 타이타닉에서는 누가 살아남았을까? (0) | 2019.12.22 |
| 7주차 데이터로 타이타닉을 분석하라 (0) | 2019.11.20 |
| ~중간점검~ (0) | 2019.11.13 |
| 6주차 내 마음대로 움직이는 로봇 브라우저 (0) | 2019.11.13 |



